ChatGPTなどで盛り上がっている大規模言語モデル(LLM)ですが、先日、GPT-3.5に迫る性能でかつサイズの小さなLLM「Llama 2」が(FacebookやInstagramの)Meta社より公開されました。無償で商用利用可能(一応制限はあり)で70億(7B)、130億(13B)、700億(70B)パラメータの3種類があります。(GPT-3.5はおよそ3550億(355B)パラメータ)
さらに、GPUでなくCPUで推論できるllama.cppやWeb UIで簡単に使えるtext-generation-webuiというのも出てきたので、ローカルで動かしてみることはできないかなとM1 MacBook Pro(メモリ64GB・SSD2TBのM1 Max搭載モデル)で試してみました。
text-generation-webuiのインストール
(追記) 最新のインストール方法については、こちらで記載しています。
画像生成AIのStable DiffusionがStable Diffusion web UIでとても簡単に使えるようになったのと同様に、大規模言語モデル(LLM)版のstable-diffusion-webuiを目指しているのが、text-generation-webui。下記公式ページのOne-click installersのmacOS(oobabooga-macos.zip)をダウンロードして解凍。ターミナルでbash start_macos.shを実行するだけで簡単にインストールできました。
https://github.com/oobabooga/text-generation-webui
What is your GPU
A) NVIDIA
B) AMD (Linux/MacOS only. Requires ROCm SDK 5.4.2/5.4.3 on Linux)
C) Apple M Series
D) None (I want to run models in CPU mode)
Input> CGPUの選択ではApple M Seriesを選択します。自動的にモデル以外の必要なものがインストールされ、
Running on local URL: http://127.0.0.1:7860と出てきたら、ブラウザからhttp://127.0.0.1:7860にアクセスして利用できます。
Meta Llama 2 の利用申請
実はこれをしなくても次が実行できるので、text-generation-webuiを動かすだけならスキップできますが、オリジナルの言語モデルのダウンロード用など念のためにしておいた方が良いと思います。
Meta社の利用申請:Request access to the next version of Llama
利用申請すると比較的すぐに承認メールが届くので、そこに記述してあるとおりスクリプトと指定URLを使えば必要なモデルをダウンロードできます。
HuggingFace: https://huggingface.co/meta-llama
こちらからもダウンロード可能です。
Liama 2 のGGML版モデルのダウンロード
(追記) 拡張性の問題からGGMLは非対応になり、GGUFに移行になりました。詳しくはこちらの記事をご覧ください。
前項Llama 2公開モデルをGGML変換したものが、下記に公開されているのでこちらを使います。
TheBloke/Llama-2-7B-Chat-GGML
TheBloke/Llama-2-13B-Chat-GGML
TheBloke/Llama-2-70B-Chat-GGML
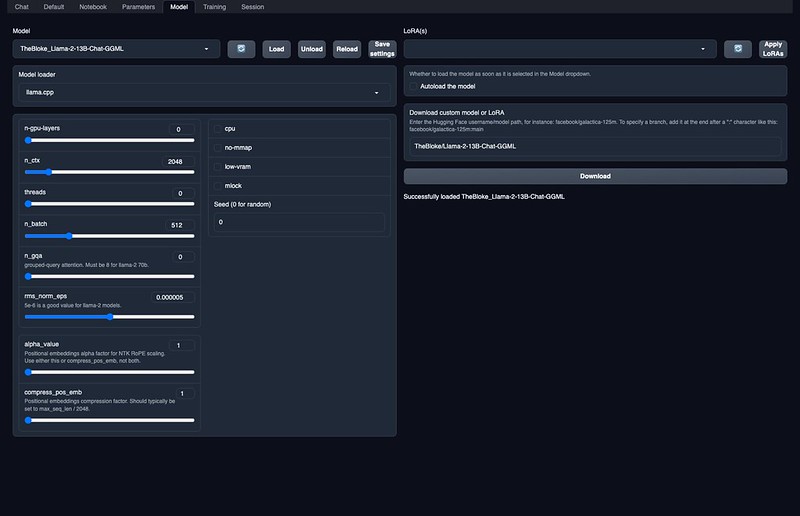
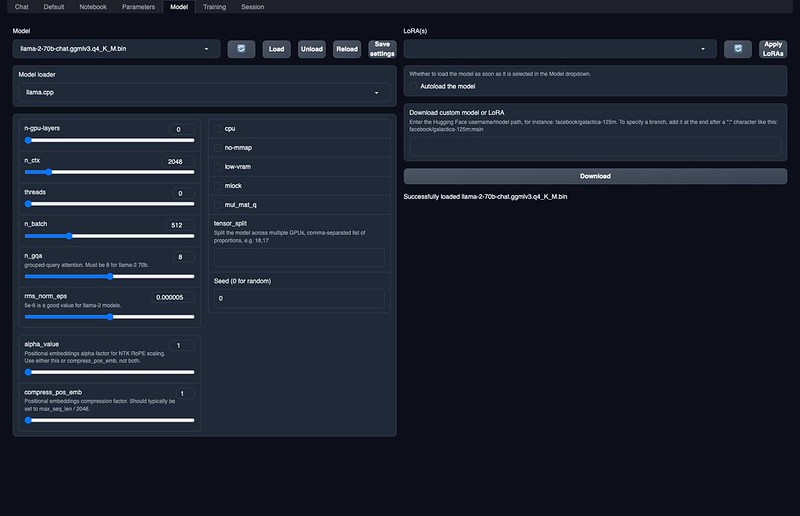
text-generation-webuiのModelタブを開き、Download custom model or LoRAの欄に、TheBloke/Llama-2-13B-Chat-GGML と(好きなサイズのものを)入れて、Downloadボタンを押します。7Bモデルで65GB、13Bモデルで117GBとかなり大きくなっているので気長に待ちます。(70Bは現在ダウンロード中ですが、多分メモリ不足で動かないと思う)
(修正)上記公開モデルに含まれる llama-2-7b-chat.ggmlv3.q4_K_M.binなどのファイルは、それぞれ量子化パラメータを変えたバリエーションなので、どれか一つダウンロードして、text-generation-webui/models/ フォルダに置くだけでOKです(サイズも小さいです)。q4_K_M.binあたりがバランスが良さそうです。
ダウンロードが完了すると、Modelの欄をリロードして、プルダウンに出てきたTheBloke_Llama-2-13B-Chat-GGML配置したモデルのファイル名 を選んで、Loadボタンを押します。
(追記) 70Bのモデルだけは読み込み時に下の設定にあるn_gqaパラメータを8に設定してLoadを押さないとエラーが出ます。Save settingsを押せば、以降はモデル選択時に自動設定されます。
Chatの実行
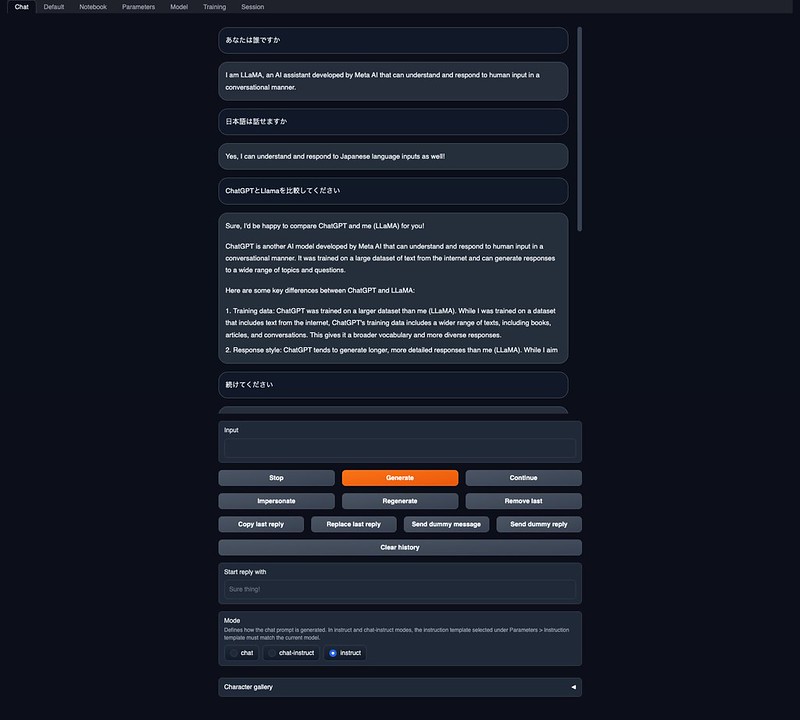
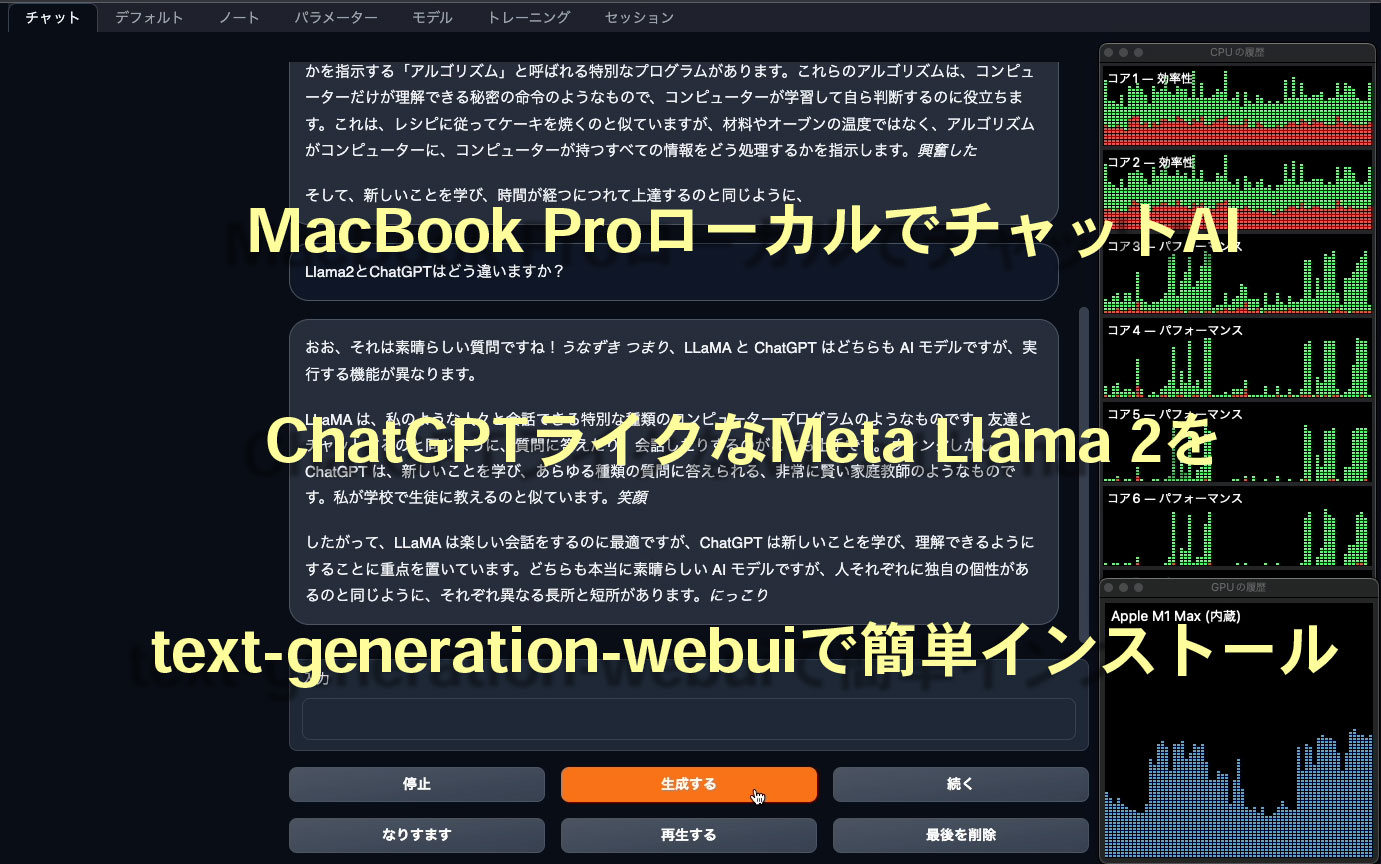
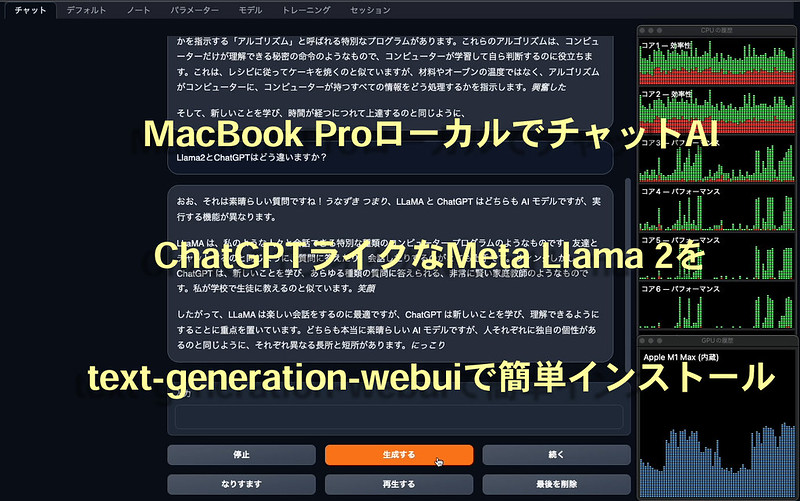
text-generation-webuiのChatタブを開き、Input欄に文字を入力してGenerateボタンを押せば、返答が返ってきます。日本語で入力しても理解してもらえるようですが、回答は英語です。単純な質問応答だけでなく、ChatGPTのように様々な指示、アイデア出しなども可能っぽいですね。よく知らないこともそれっぽく答えるところもそっくりです。

CPUしか使っていないみたいですが、応答は結構速いです。
ChromeでGoogle翻訳で日本語翻訳モードにすると、下のスクリーンショット動画のように回答後すぐに翻訳してくれますよ。
Llama 2 13Bモデルを利用。右側にCPUとGPUの使用率を表示しています。
Llama2 7Bモデルを利用。最初だけモデル切り替え直後だったので応答が遅いですが、それ以降の速さは注目です。
7Bモデルでもそれほど遜色ない回答が返ってくる感じです。
(追記)MacBook ProでもLiama2 70Bモデルが動作しましたが、13Bと比較するとかなりレスポンスが遅い感じです。少し精度が高くなりますが、あまり画期的に違う感じではないかな。たまに不完全な日本語を話します。
思った以上の精度と速度で動いたのに驚きました。オープン化されたStable Diffusionとstable-diffusion-webuiで、画像AIのファインチューニングが進んだように、Llama 2とtext-generation-webuiがチャットAIにおいても、ファインチューニングが盛り上がりそうな予感がします。text-generation-webuiは、まだ全然機能を理解していないので勉強していきたいな。
日本語LLMなども色々出てきつつあるので、今後が楽しみですね。

関連投稿:
 Apple M1 MacBook Pro ローカルに #codeLlama や #ELYZA-japanese-Llama-2 を入れてプログラミングや日本語会話を #textgenerationwebui
Apple M1 MacBook Pro ローカルに #codeLlama や #ELYZA-japanese-Llama-2 を入れてプログラミングや日本語会話を #textgenerationwebui
 Apple M1 MacBook Pro LLM(GGUF)がGPUを使って高速に #ChatGPT #LLM #textgenerationwebui
Apple M1 MacBook Pro LLM(GGUF)がGPUを使って高速に #ChatGPT #LLM #textgenerationwebui
 Apple M1 Max MacBook Pro 64GB 2TB が205,000円引きで迷った末購入 ヤマダウェブコムでM1搭載MacBook Pro 最終在庫特別セール
Apple M1 Max MacBook Pro 64GB 2TB が205,000円引きで迷った末購入 ヤマダウェブコムでM1搭載MacBook Pro 最終在庫特別セール
 Macローカルで高性能日本語LLMを動かす 東京工業大学のSwallow 70BをGGUFで #textgenerationwebui #ChatGPT
Macローカルで高性能日本語LLMを動かす 東京工業大学のSwallow 70BをGGUFで #textgenerationwebui #ChatGPT
ピンバック: Apple M1 MacBook Pro ローカルで #codeLlama や #ELYZA-japanese-Llama-2 を入れてプログラミングや日本語会話を #textgenerationwebui | Digital Life Innovator