
先日、ACE Step v1による作曲を紹介しましたが、よりSunoに近いインターフェースで日本語の楽曲生成もより精度高くできるHeartMuLaが1月14日にオープンソースでリリース。早速、RTX5070Ti搭載PCで試してみました。
コンテンツ目次
作詞・作曲・歌・演奏:HeartMuLa Studio + Ollama + gpt-oss-20b

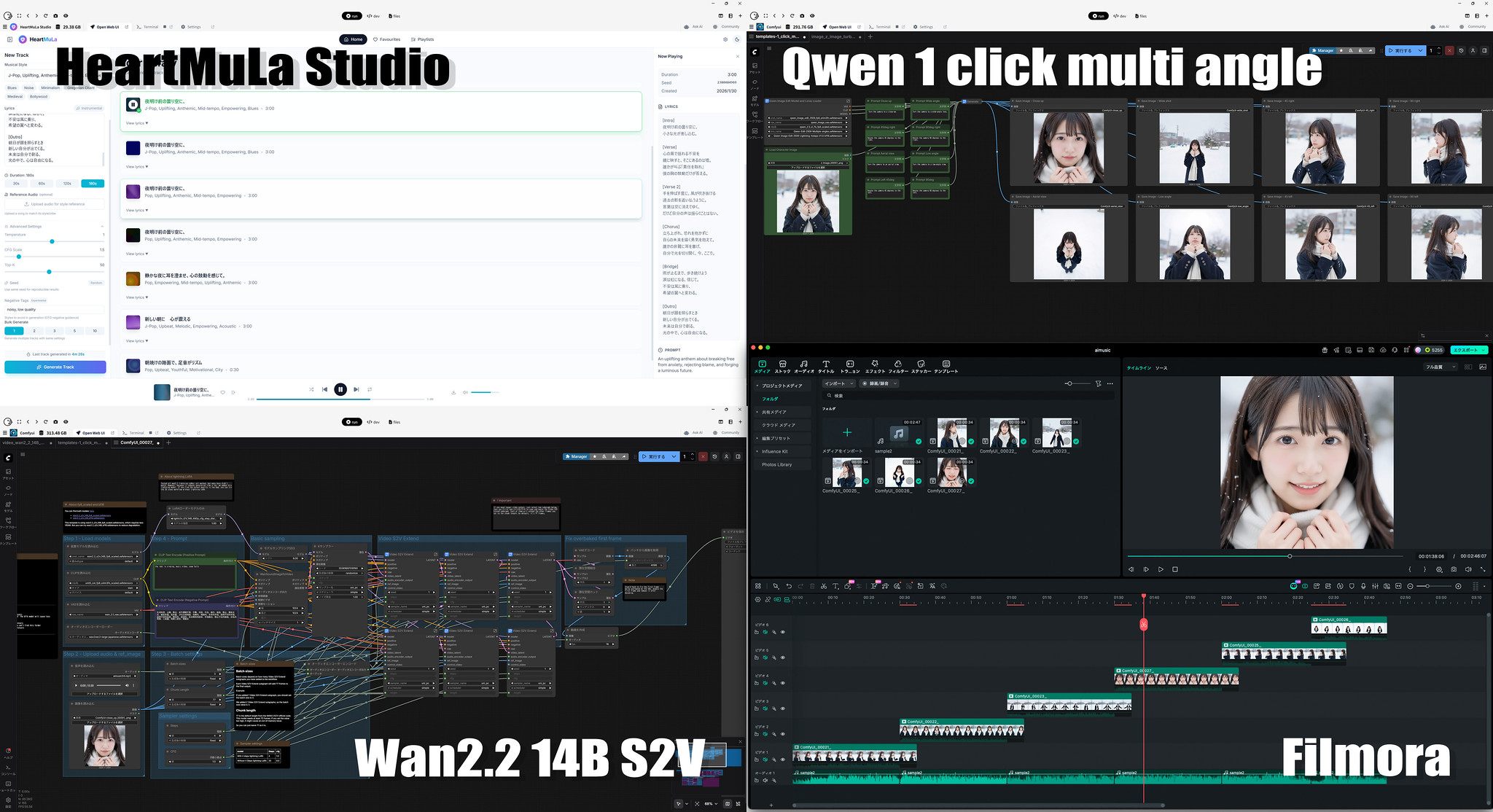
HeartMuLa StudioはPinokioで簡単にインストールして使えるようになっています。

モデル等がダウンロードされ画面が立ち上がりました。基本的に、スタイルと歌詞を入力するだけで音楽が生成できますが、LLMと連携して、曲のコンセプトを入力するだけで、スタイルと歌詞をLLMで生成してくれるという機能もあり、概要だけ指示すればあとはすべてAIが作詞・作曲してくれます。

ローカルでLLMを起動していれば、それを使うこともできます。OllamaでOpenAI互換APIを立ち上げていたのでそちらを使うことに。モデルはgpt-oss:20bを指定しました。
再起動すると、Custom: gpt-oss:20b が選べるように。言語はJapaneseを指定。

まず日本語でSony Conceptを入力して横の生成アイコンを押すと、Sony Concept, Musical Style, Lyricsが生成されます。Japanese を指定していれば歌詞は日本語になります。生成されたものは編集可能なので、気になるところなどは直して、Generate Trackを押すと、曲が生成されます。同じスタイル・歌詞でも生成毎に違った感じになります。生成中にキューに追加することもできますし、まとめて複数曲生成させるようにすることも可能。
適当にコンセプトを入力して、スタイル・歌詞はあえて編集せず作成してみた結果が下記です。
日本語はかなりまともに歌ってくれます(たまに読み間違えたり、ちょっとネイティブじゃないK-POPアーティストが歌っている感じになりますが)。曲が変なことはよくありますので、何度もガチャしたくなりますが、すべてローカル動作なので課金も発生しないのが良いですね。
冬の恋人たち、喧嘩と仲直りみたいなテーマで曲をつくってみました。
同じスタイル・歌詞で生成しても全く違う曲が生成されます。
バレンタインがテーマ。2人で歌っているように聞こえるのでデュエットなども作れるのかな?と少し試したりしてみましたが、うまくいきませんでした。曲調もあまり指定した感じにならないので、もう少し使い方を色々試してみたいと思います。
ちなみにRTX5070Tiだと、3分の曲生成に5分程度かかりました。
マルチアングル写真:Z-Image-Turbo + Qwen Image Edit 1 click multi character angles

生成した曲でリップシンク動画を作ろうかなと、Z-Image-Turboで写真を生成。ただリップシンク動画は一度にあまり長い時間は生成できないので、Qwen Image Edit 1 click multi character anglesを使って、1枚の写真のキャラクターを様々なアングルからの写真に変換し、シーンを変える感じにしました。(キャラクターの一貫性を保つ画像編集などを使っても良いと思います)。
Qwen Image Edit 1 click multi character angles はたった1枚から見えていない部分も含めて生成されていてすごいと思いつつ、処理は結構時間がかかりますね。8枚生成に1時間半くらいかかっていました。
リップシンク動画:Wan2.2 14B S2V

曲を歌っていない部分で切り分け、それぞれの曲とマルチアングルの写真を指定して、Wan2.2 14B S2Vでリップシンク動画を生成。
Wan2.2 14B S2Vのデフォルトテンプレートでは、あまり口が合わなかったので、下記のmodel.safetensorsをwav2vec2-large-japanese.safetensorsとリネームして、audio_encordersに入れて使っています。(それでもあまり合っていないように見える部分がありますが)
1024×1024の35秒の動画生成に約1時間くらいかかっていたので、寝ている間に6本生成。切り替えタイミングの自由度を上げるため各パートの音楽より少し長めに生成するのが良いです。
動画編集:Flimora

各パートで生成された動画を音に合わせて繋ぎ合わせたのが下記MVです。
細かいところを気にせず、とりあえず生成してみたものなのでとても適当ですが、ローカルAIでどんな感じのMVが作れるのかの参考程度に。作詞・作曲・歌・カメラすべてAIがやっており、すべてローカルPCで動作というのがすごいです。
もっと細かく調整したり、ガチャを回したり、人が手を加えたりすればクオリティーはより高くなるかと思います。


ピンバック: 簡単・高速にさまざまなスタイルの楽曲生成 進化したローカル音楽生成AI ACE Step 1.5 #生成AI | Digital Life Innovator