
先日、text-generation-webuiを使った、MacでのMeta Llama2の簡単な利用方法を紹介しましたが、そこで使っていたllama.cppのGGML対応がなくなり、GGUFに移行しました。何でもGGMLには拡張性に問題があったため、より汎用的に使えるGGUFフォーマットに移行したみたいです。
最新のtext-generation-webuiでもGGMLモデルが使えなくなったため、GGUFに変換する必要があります。
https://github.com/ggerganov/llama.cpp
モデルは公開されているものをダウンロードするのでも良いですが、Llama 2のGGMLv3モデルについては上記をインストールして、下記のような感じで変換した方が速いかも。
python convert-llama-ggmlv3-to-gguf.py --input llama-2-7b-chat.ggmlv3.q4_K_M.bin --output llama-2-7b-chat.q4_K_M.gguf
python convert-llama-ggmlv3-to-gguf.py --input llama-2-13b-chat.ggmlv3.q4_K_M.bin --output llama-2-13b-chat.q4_K_M.gguf
python convert-llama-ggmlv3-to-gguf.py --input llama-2-70b-chat.ggmlv3.q4_K_M.bin --output llama-2-70b-chat.q4_K_M.gguf --gqa 8変換したGGUFモデルをtext-generation-webui/modelsに配置して、Loadすれば今まで通り使えました。(70bのgqaオプションもモデルに埋め込まれるため、指定する必要なくなりました)
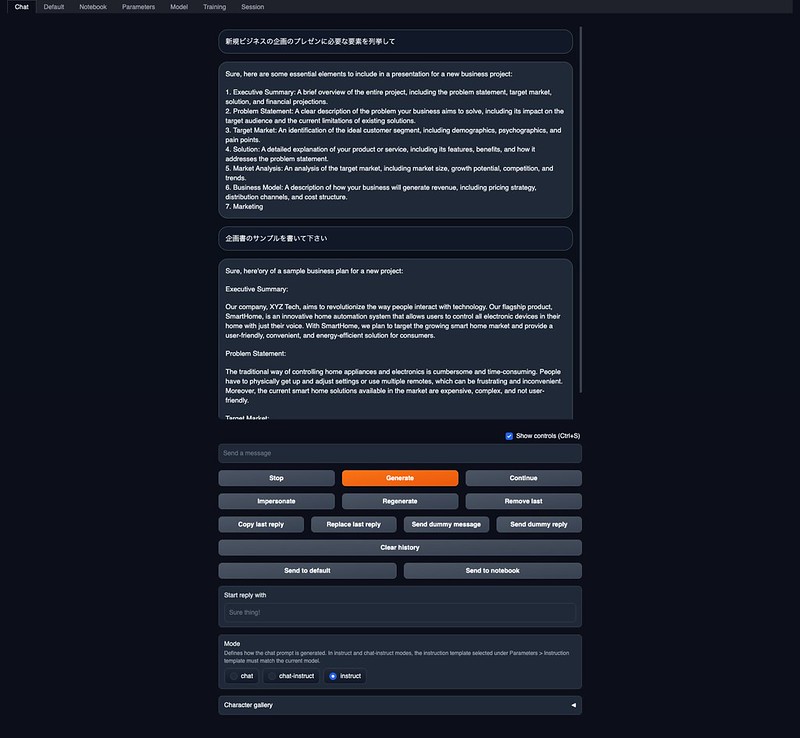
東京大学 松尾研究室発のAIスタートアップのELYZAが公開した日本語対応のLLM「ELYZA-japanese-Llama-2-7b-fast-instruct」も使ってみました。これはMetaのLlama-2-7b-chatに対して、日本語の語彙を追加し、約160億トークンの日本語テキストで追加事前学習を行ったモデル(推論速度に換算すると約1.82倍高速に動作するそう)。さらにユーザーからの指示に従い様々なタスクを解くことを目的として、事後学習も行っているものになります。

このモデルをGGUFに変換したものが下記に公開されているので、ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.ggufをダウンロードして、text-generation-webui/modelsに配置して読み込みます。
https://huggingface.co/mmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-gguf/tree/main

日本語で応対するようにCharacterを定義しました。
日本語での応対はかなり高速です。内容はかなりいい加減だったり、変な応対をすることもありますが、しっかり回答することもあります。
CyberAgentやLINE、松尾研究室が公開している日本語LLMもGGUFに変換されたものが公開されていたりしますが、これらのGPT-NeoX系のモデルは現状はllama.cppが対応していないので読み込みエラーになるようです。これらにも対応できるようにGGUFに移行したのだと思っているので、そのうち動くようになるかも。
https://github.com/facebookresearch/codellama
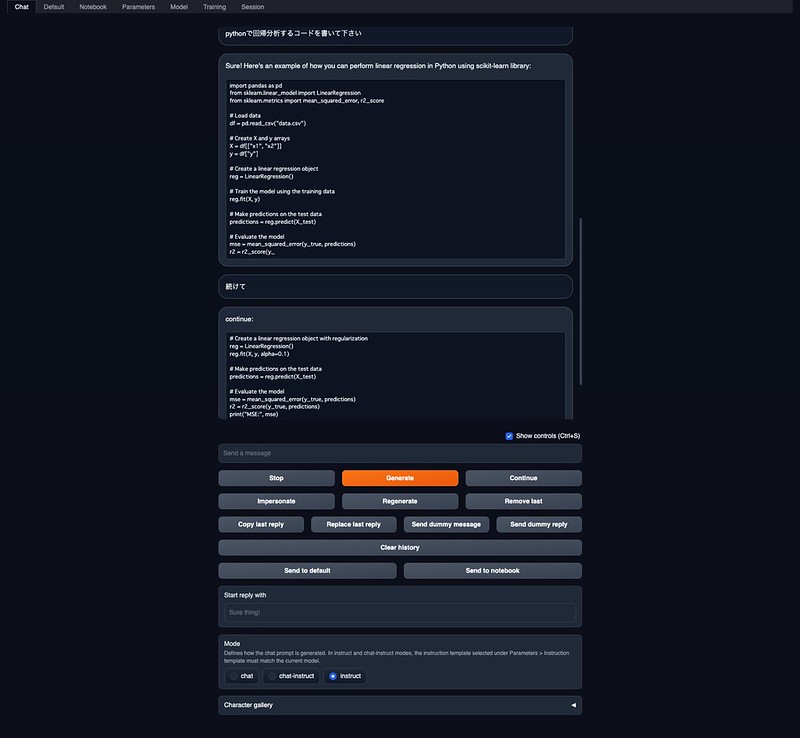
Metaが公開したコード生成用のモデル、codeLlamaも下記などでGGUFに変換したものが公開されています。codellama-34b-instruct.Q4_K_M.ggufをダウンロードして、text-generation-webui/modelsに配置して読み込みます。
https://huggingface.co/TheBloke/CodeLlama-34B-Instruct-GGUF
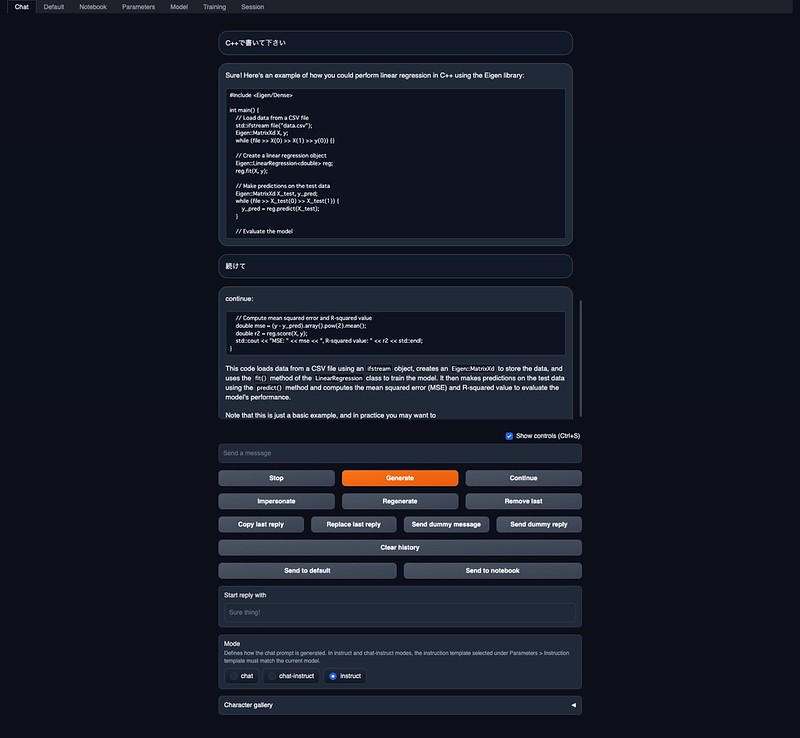
それっぽいコードが生成されますね。全く違うコードを生成したりもしますが(笑)
変化が激しくて大胆に変更なんてこともありますが、手持ちのPC/Macで手軽に生成AIが動くのは面白いですね。



ピンバック: Apple M1 MacBook Pro ローカルに ChatGPTライクなLLM Meta Llama 2 を簡単インストールする方法 #textgenerationwebui #ChatGPT #Llama2 | Digital Life Innovator
ピンバック: Apple M1 MacBook Pro LLM(GGUF)がGPUを使って高速に #ChatGPT #LLM #textgenerationwebui | Digital Life Innovator