


MacのStable Diffusion web UIで、画像からプロンプトを生成して似た感じの画像を生成することができるip-adapterを動かす方法がわかりましたのでその紹介と、以前LoRAと実写系モデルを使ったAIコスプレ写真を紹介しましたが、もっと簡単に1枚の画像から似た感じのAIコスプレ写真を生成する方法を紹介します。
また、以前mov2movを使った動画からAI動画を生成する方法を紹介しましたが、AnimateDiffを使い、テキストから短い一貫性のあるAI動画を生成する方法も紹介します。
ControlNet ip-adapter
ip-adapterはControlNetをインストールすれば使えるのですが、Macでは全然似た画像が生成できないなと思っていました。よく見ると、下記のようなエラーが出て動いていないようでした。
RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False. If you are running on a CPU-only machine, please use torch.load with map_location=torch.device('cpu') to map your storages to the CPU.動かすためにはテキストエディタなどで、下記ファイルを書き換える必要があります。
/stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/clipvision/__init__.py
の
clip_vision_h_uc = torch.load(clip_vision_h_uc)['uc']
と書かれているところを
clip_vision_h_uc = torch.load(clip_vision_h_uc, map_location=torch.device('cpu'))['uc']
に書き換えます。さらに起動時に ./webui.sh –no-half のように–no-halfオプションを付けて起動することで、ip-adapterが使えるようになります。
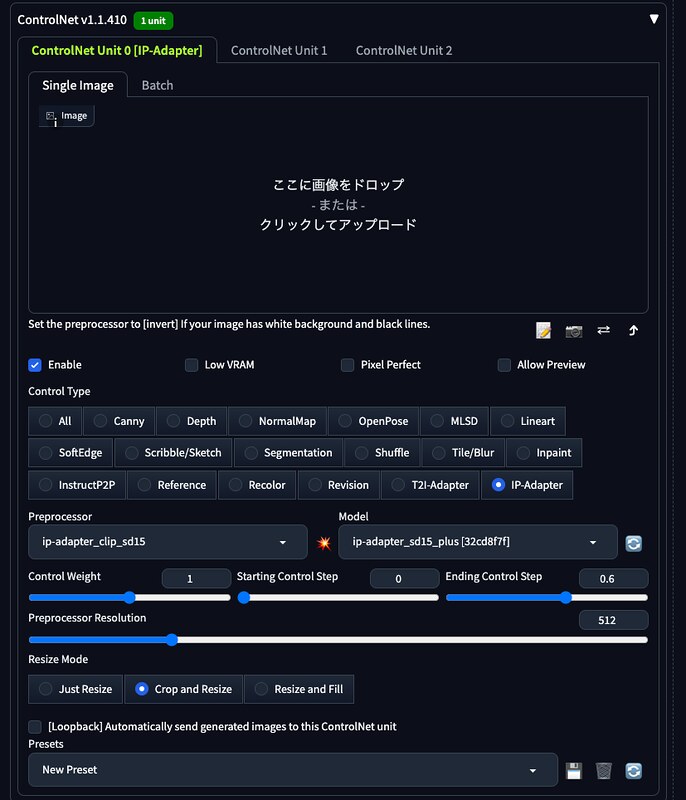
ControlNetのControl TypeとしてIP-Adapterを選び、PreprocessorとModelを、
Stable Diffusion v1.5のモデルの場合は、ip-adapter_clip_sd15とip-adapter_sd15_plusにします。
Stable Diffusion XLのモデルの場合は、ip-adapter_clip_sdxlとip-adapter_xlにします。
image欄に画像をドロップして、生成すると特にプロンプトを書かなくても、画像そっくりの絵が生成されるようになりました。img2imgだと元画像を指定した画像のキャラクターなどのイメージで書き換えることも可能です。
Stable Diffusion v1.5のモデルを使って、AIコスプレ写真を作るには、実写系のモデルを選んで、プロンプトは画像のクオリティーを上げるようなプロンプト・ネガティブプロンプトを中心に書いて、Ending Control Stepを0.6くらいに設定します。Sampling stepsは40くらいに、CFG Scaleは10くらいの高い値にした方が良さそうです。
このようにすることで、前半のステップでは、入力した画像そっくりのアニメ画像を生成しつつ、後半では実写系モデルによりコスプレ風にすることができました。(ちなみに、SDXLのモデルでは実写系にならず、アニメのままになる感じでした。)
学習しなくても1枚の画像から生成できるのは面白いですね。
下記に生成してみたサンプルを載せておきます。元画像が何のキャラクターか分かるでしょうか?















AnimateDiff
AnimateDiffはExtensionsタブで下記URLを指定して読み込みます。
https://github.com/continue-revolution/sd-webui-animatediff.gitさらに、ここのどこかから、animatedfiffMotion_v15V2.ckptなどのモデルをダウンロードして、/stable-diffusion-webui/extensions/sd-webui-animatediff/model/ に配置します。
今のところSDXL対応はしていないようです。
ERRORが出ていたので、これもExtensionsに入れました。
https://github.com/deforum-art/deforum-for-automatic1111-webui.git(追記)さらにシーンが途中で変わってしまうような現象(一貫性がなくなる)を避けるために、SettingsタブのOptimizationsで、「Pad prompt/negative prompt to be same length」にチェックを入れた方が良いみたいです。
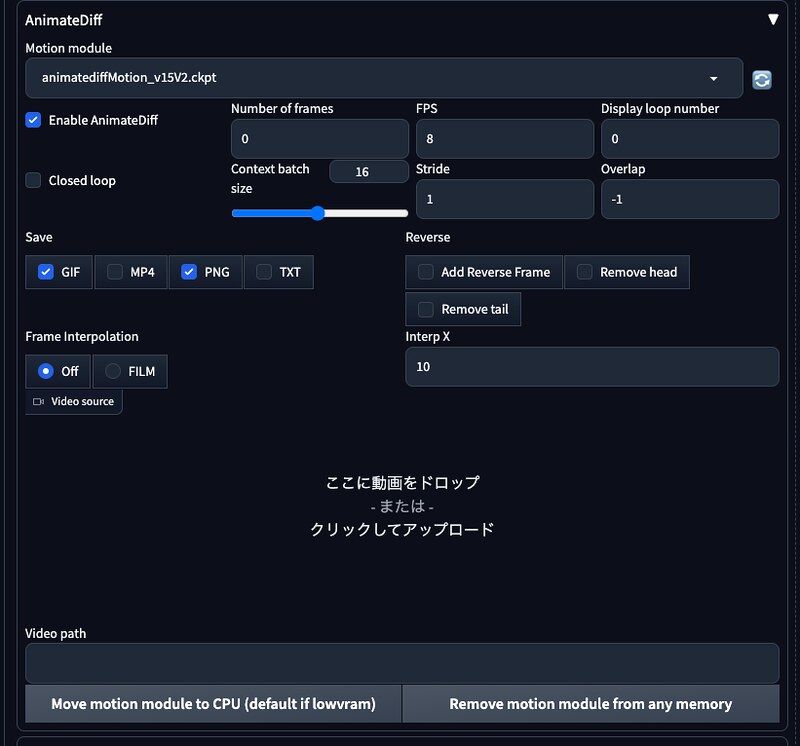
AnimateDiffのMotion moduleでモデルを選択して、Enable AnimateDiffにチェックを入れると、txt2imgやimg2imgで静止画じゃなく、動画が生成されるようになります。FPSやNumber of framesなども設定できます。
どんな動きになるのか、色々試してみました。生成にはそれなりに時間がかかります。
思った以上に動き、一貫性があり破綻もない感じで良いですね。

花火の動きはとてもリアルで良いですね。

人が回転したりもできます。

雨なんかも

歩くのもできますね。







AnimateDiffとip-adapterを併用することもできるので、好きなキャラクターを動かすこともできますが、今のところあまり良い感じのができていないです。
関連投稿:
 Macローカルの Flux.1 dev + Comfyui で LoRA や IP Adapter などの ControlNet を動かしてみました #Flux #Mac
Macローカルの Flux.1 dev + Comfyui で LoRA や IP Adapter などの ControlNet を動かしてみました #Flux #Mac
 Apple M1/M2 Mac に Stable Diffusion web UI をインストールする方法 #StableDiffusion #BRAV5
Apple M1/M2 Mac に Stable Diffusion web UI をインストールする方法 #StableDiffusion #BRAV5
 Stable Diffusion web UI v1.6.0 で 次世代 #StableDiffusion (#SDXL) が簡単に使えるようになりました
Stable Diffusion web UI v1.6.0 で 次世代 #StableDiffusion (#SDXL) が簡単に使えるようになりました
 #StableDiffusion XL (#SDXL) の ControlNet や チューニングモデル・マージモデル を試してみました
#StableDiffusion XL (#SDXL) の ControlNet や チューニングモデル・マージモデル を試してみました
ピンバック: 2023年の振り返り | Digital Life Innovator