


Apple M1 MacBook Proのローカルで動かしていたText Generation WebUIが大幅に変更があったみたいなので、再度インストールしました。GPUも問題なく使えるようになり、MetaのLlama 2 70Bを含め大規模言語モデル(LLM)がかなり高速に動くようになりました。
基本は上記と同じですが、下記のようにしてGPUを使えるようにllama-cpp-pythonをインストールしています。
途中エラーが出ましたが、Xcodeが最新になっていなかったためでした。
GGUFのモデルファイルはtext-generation-webui/modelsに入れます。
git clone https://github.com/oobabooga/text-generation-webui.git
cd text-generation-webui
./start_macos.sh
./update_macos.sh
pip install -r requirements_nowheels.txt
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
bash Miniforge3-MacOSX-arm64.sh
conda create -n llama python=3.9.16
conda activate llama
pip uninstall llama-cpp-python -y
CMAKE_ARGS="-DLLAMA_METAL=on" pip install -U llama-cpp-python --no-cache-dir
pip install 'llama-cpp-python[server]'
./start_macos.shさらにモデルを読み込むときに、Model loderをllama.cppに、n-gpu-layersを30にthreads, threads_batchを8に設定しています。(M1 MaxはCPUが10コア、GPUが32コアなので。メモリが64GBでメモリ不足ならないのも良いですね。)
Parameters/Generationのmax_new_tokensを2048くらいにしました。
コンテンツ目次
Llama-2-70B-GGUF
llama-2-70b.Q4_K_M.gguf

最初の会話は時間がかかりますが、それ以降は驚くほど早く返答が返ってきました。CPUだけのときと比べると動作がかなり速いです。トークンを大きくした影響か、かなり長い返答になりました。

日本語もある程度話せるようですが、トークンが1文字ずつになるようで遅くなりますね。
ELYZA-japanese-Llama-2-7b-fast-instruct-gguf
ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf
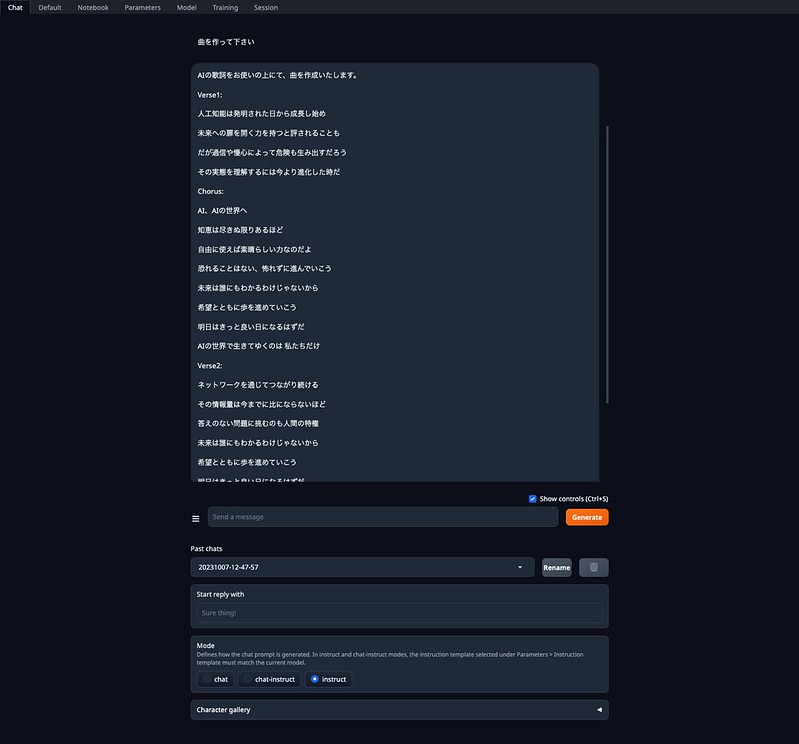
サクサク日本語で返答が返ってきます。比較的短い返答が多いですが、内容によっては長い返答も。
CodeLlama-34B-Instruct-GGUF
codellama-34b-instruct.Q4_K_M.gguf

こちらもかなり早くなりました。プログラムの返答もかなり長いです。予想通りそのままでは動きませんでしたが、それっぽいコードを書いていますね。
(アイキャッチ画像はStable Diffusionで生成したものです)
関連投稿:
 Apple M1 MacBook Pro ローカルに ChatGPTライクなLLM Meta Llama 2 を簡単インストールする方法 #textgenerationwebui #ChatGPT #Llama2
Apple M1 MacBook Pro ローカルに ChatGPTライクなLLM Meta Llama 2 を簡単インストールする方法 #textgenerationwebui #ChatGPT #Llama2
 Apple M1 MacBook Pro ローカルに #codeLlama や #ELYZA-japanese-Llama-2 を入れてプログラミングや日本語会話を #textgenerationwebui
Apple M1 MacBook Pro ローカルに #codeLlama や #ELYZA-japanese-Llama-2 を入れてプログラミングや日本語会話を #textgenerationwebui
 Apple M1 Max MacBook Pro 64GB 2TB が205,000円引きで迷った末購入 ヤマダウェブコムでM1搭載MacBook Pro 最終在庫特別セール
Apple M1 Max MacBook Pro 64GB 2TB が205,000円引きで迷った末購入 ヤマダウェブコムでM1搭載MacBook Pro 最終在庫特別セール
 Macローカルで #DeepSeek 日本語版 を簡単に動かす方法 DeepSeek-R1-Distill-Qwen-32B-Japanese #LLM #LMStudio #ChatGPT
Macローカルで #DeepSeek 日本語版 を簡単に動かす方法 DeepSeek-R1-Distill-Qwen-32B-Japanese #LLM #LMStudio #ChatGPT
ピンバック: Apple M1 MacBook Pro ローカルに ChatGPTライクなLLM Meta Llama 2 を簡単インストールする方法 #textgenerationwebui #ChatGPT #Llama2 | Digital Life Innovator
ピンバック: Macローカルで簡単にAI音楽生成 #AudioCraft #MusicGen #AudioGen #TTSGenerationWebUI | Digital Life Innovator
ピンバック: Macローカルで高性能日本語LLMを動かす 東京工業大学のSwallow 70BをGGUFで #textgenerationwebui #ChatGPT | Digital Life Innovator