


AI画像生成のStable Diffusion web UI、AIテキスト生成のText Generation WebUIとくれば、次はAI音楽生成ですよね。音楽生成といえば、MetaがAudioCraftという音楽・音声生成AIを公開しているのですが、これを簡単に使えるTTS Generation WebUIをMacにインストールして使ってみました。
TTS Generation WebUI
TTSというのはText to Speechで音声合成機能もあるのですが、MetaのAudioCraftにも対応しています。One click installersにMac用のインストーラーもあるのですが、うまくインストールできませんでしたので、手動でインストールしました。と言ってもとても簡単です。
git clone https://github.com/rsxdalv/tts-generation-webui.git
conda create -n tts python=3.10
conda activate tts
pip install -r requirements.txt
pip install -r requirements_audiocraft.txt 「ERROR: No matching distribution found for xformers==0.0.19」というエラーで止まってしまったので、requirements_audiocraft.txtの3行目を「# xformers==0.0.19 # For torch==2.0.0 project plane」としてコメントアウト。
pip install -r requirements_audiocraft.txt
python server.py 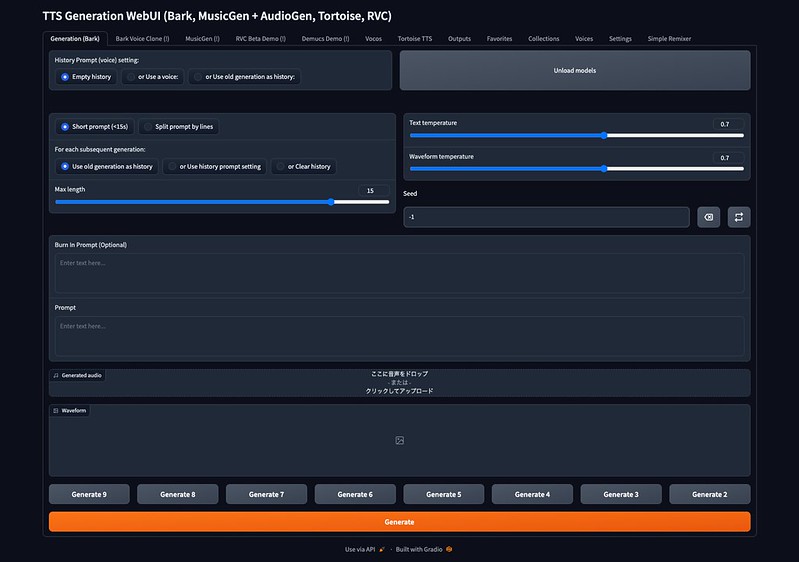
このようなページがブラウザで立ち上がります。
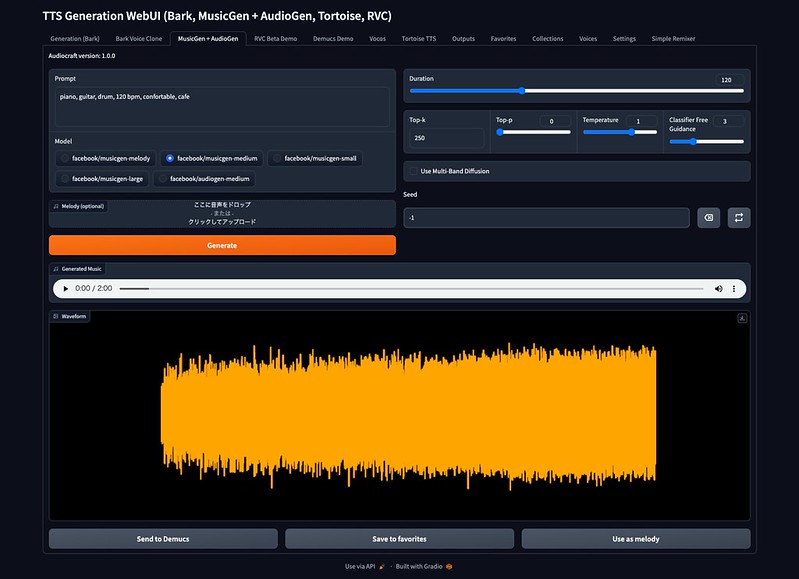
「MusicGen + AudioGen」タブを押して、Promptに生成したい音楽について記述します。
Modelはfacebook/musiicgenが音楽用のモデル、facebook/audiogenが効果音などのオーディオ用のモデルです。musicgenはmelody/small/medium/largeがありますね。
Durationに生成したい音楽の秒数を入れて、Generateを押すと、音楽が生成されます。最初に自動的にモデルがダウンロードされます。
MacだとまだGPUが使われないようですが、CPUで動きます。短い音楽でもかなり生成に時間がかかります。smallで実時間の9倍、mediumで34倍、largeで56倍くらいかかりました。同じような繰り返しだったり、音楽として変だったりしますが、プロンプトで指定した感じは出ています。でも画像やテキストと違って、プロンプトでどういうキーワードを指定すれば良くなるのかが難しいですね。
時間さえかければ120秒の音楽も生成できました。
AudioGenは川音と鳥の鳴き声みたいなのを生成してみましたが、生成できました。
どこまでできるのか色々試してみたいと思います。
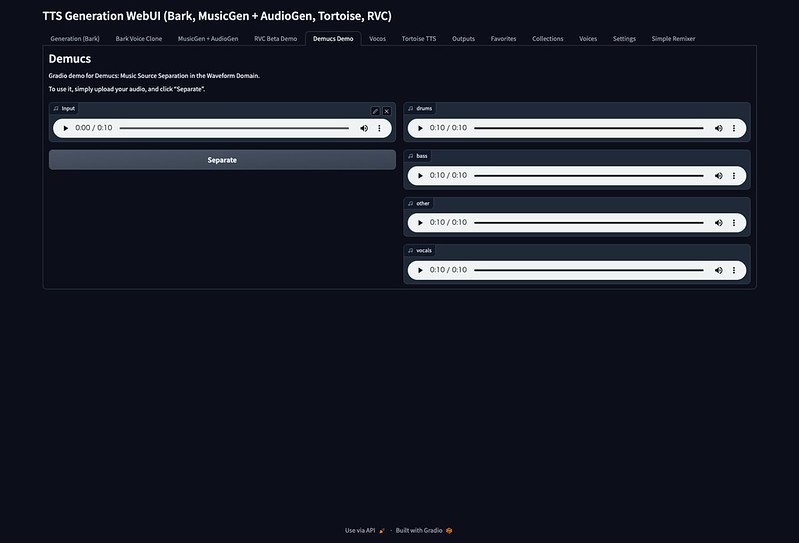
ちなみに「Demucs Demo」タブを使うと、音楽をドラム、バス、ボーカル、その他に分けることができます。
TTSのBark, Tortoise, ボイスチェンジャーのRVCについてはまだ使い方が良くわかっていないので、そのうち使ってみたいと思います。


ピンバック: 2023年の振り返り | Digital Life Innovator