

Ubuntu 18.04を入れてデュアルブート化した、RTX2060搭載のDELL G5 15。色々インストールしてみて遊んでいます。
様々な面白い技術がオープンソースとして無料で公開されているので、とりあえず興味があるものを動かしてみるだけでも楽しいですね。なかなかうまくいかないので大変だったりもしますが、先人のノウハウがネットに溢れているので検索すれば解決策がみつかったりするのも良いです。参考にしたURL等を合わせてメモしておきます。
デザイン
技術じゃないですが、最初にUbuntuのデザインをMac風に変更。McMojaveテーマとgnome-sushiというQuick Lookのような機能が便利です。

画像処理
コンピュータービジョンのライブラリ「OpenCV」は、昔から使っていましたが、とても多彩な画像処理機能が使えてとても便利です。
インストールが少し大変ですが、GPUを使うようにソースからビルドしました。
テストで顔認識や目の認識なんかのサンプルを動かしてみました。

GitHub: OpenCV: Open Source Computer Vision Library
https://github.com/opencv/opencv
OpenCV 最新版のビルドとインストール,CUDA 対応可能(ソースコードを使用)(Ubuntu, Debian 上)
https://www.kkaneko.jp/tools/ubuntu/ubuntu_opencv_buildout.html
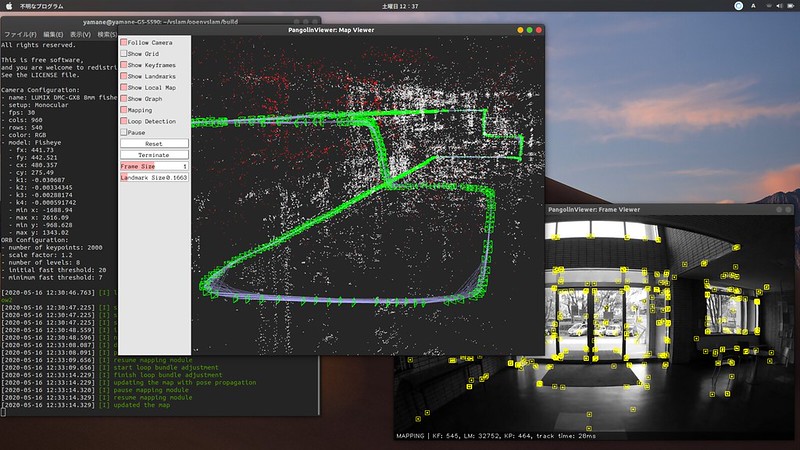
Visual SLAM(Simultaneous Localization and Mapping)
SLAMは自己位置を推定しながら周りのマップを作成する技術。自動運転車やルンバなどがマップを作成したりホームベースに戻ったりするのにつかわれている技術ですね。ビジュアルSLAMはカメラの映像から特徴点を抽出し、その動きで自己位置を推定します。
「OpenVSLAM」では、動画から自己位置を推定してマップと経路を作成するサンプルを動かしてみました。
OpenVSLAM
https://openvslam.readthedocs.io/en/master/installation.html
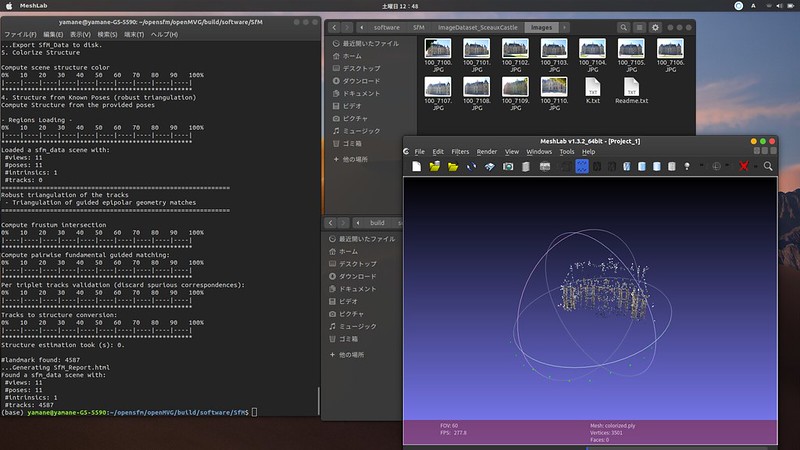
SfM (Structure from Motion)
SfM (Structure from Motion)は、多視点の写真から特徴点をマッチングさせて3次元上の位置を推定、3次元モデルを構築する技術です。
ドローンで自動撮影した写真などから簡単に3次元のモデルを作成できるのが面白いです。(仕事では商用ソフトを使っています)
「OpenMVG」は多数の写真から特徴点をマッチングして、撮影位置を推定、特徴点を3D空間上に配置します。
GitHub: OpenMVG (open Multiple View Geometry)
https://github.com/openMVG/openMVG
Structure From Motion (SfM)を試す 〜 OpenMVG編 (Ubuntu 16.04) 〜
https://qiita.com/fujin/items/d816a7e9b8c2577a7e37
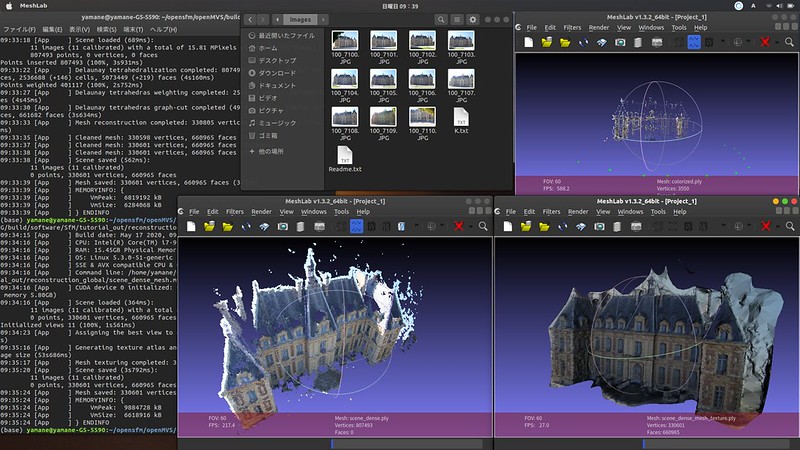
「OpenMVS」は、OpenMVGの情報を引き継いで、写真から3D点群を高密度化したモデルを作成したり、メッシュモデルにしたりします。
まだサンプルを動かした程度なので、オリジナルの写真で試してみようかな。
GitHub: OpenMVS: open Multi-View Stereo reconstruction library
https://github.com/cdcseacave/openMVS
「OpenSfM」はSfMのPythonライブラリ。Webサーバーとして点群をブラウズするような機能もあります。

SfMについて #1:OpenSfMを実行する
https://mlengineer.hatenablog.com/entry/2019/09/16/150820
Deep Learning
Deep Learning (AI)には様々な技術があり、学習済みモデルなども提供されているので、比較的簡単に遊んでみることができますが、実際に学習したり、チューニングしたりするのは大変そうですね。
「Avatarify」はいわゆるDeepfakeと呼ばれる人物画像合成技術。フェイクニュースを作るのに使われているとかでニュースとかでも話題になっていましたね。Generative Adversarial Networks (GANs)という、学習したモデルから入力画像にない本物っぽい偽物を生成することができる技術を使っています。
Avatarifyは、1枚の人物写真だけで、カメラ画像で入力した顔の動きに合わせた映像を作成することができます。しかもWebカメラとして出力できるので、Zoom等のWeb会議システムでなりすましすることができたりしてしまいます。RTX2060のおかげで24FPSぐらい出ていました。
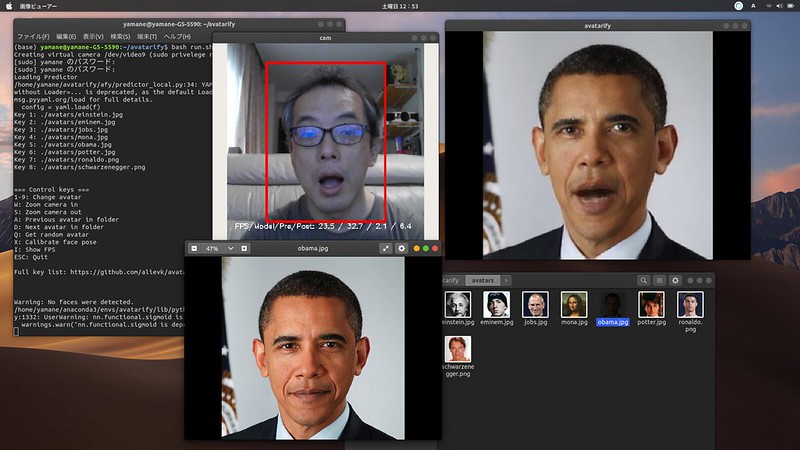
GitHub: Avatarify
https://github.com/alievk/avatarify
仮想環境を利用するためにDockerも導入。最新版はオプション指定でNVIDIA対応になっているみたいです。

NVIDIA Docker って今どうなってるの? (19.11版)
https://qiita.com/ksasaki/items/b20a785e1a0f610efa08
Pythonのバージョンやライブラリのバージョンに依存するソフトウェアも多いので、環境を分けて構築できるAnacondaも導入。
「SSD (Single Shot MultiBox Detector)」は、画像認識を行い人などのオブジェクトを検出する技術。学習したオブジェクトを入力画像から検出して、四角形で囲んだり確信度を出したりできます。
依存ソフトのバージョンが低くてエラーが色々出てまだうまく動かせていなかったりしますが、動画からオブジェクト検出することはできました。

GitHub: A port of SSD: Single Shot MultiBox Detector to Keras framework.
https://github.com/rykov8/ssd_keras
SSD: Single Shot MultiBox Detector 高速リアルタイム物体検出デモをKerasで試す
https://qiita.com/PonDad/items/6f9e6d9397951cadc6be
「Mask R-CNN」も、画像からオブジェクトを検出する技術。四角で囲むだけでなく、セグメンテーション(領域切り分け)で学習したオブジェクトの領域を塗ることができます。領域を塗らないといけないので学習させるのは大変ですが、とても面白い。
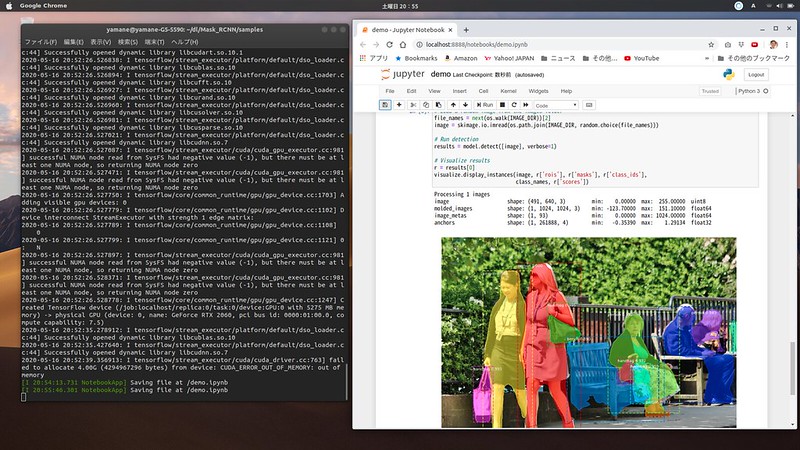
GitHub: mask-rcnn
https://github.com/nanako-ut/mask-rcnn/blob/master/maskr-cnn_keras.ipynb
Mask R-CNN(keras)で人物検出 on Colaboratory
https://qiita.com/nanako_ut/items/cb28d403fcaf013b2396
Dockerを利用して、簡単にDeep Learningの環境を構築できるNGC(NVIDIA GPU Cloud)なんてのもあります。
Deep Learningの環境構築はかなり大変なので、こういったのを利用して簡単に遊べると良いですね。

NVIDIA NGC
https://ngc.nvidia.com/
まだどれもインストールしてテストしてみただけのような状況なので、これから中身を理解して、面白いものを作れないかと思っています。



ピンバック: モノクロや線画からカラー画像を生成できたりするpix2pixが面白そう | Digital Life Innovator
ピンバック: 実物大ガンダムの動画から3Dモデルを作成してみました | Digital Life Innovator