


先日、NVIDIA RTX搭載Windows PCにかんたんにインストールできるNMKD Stable Diffusion GUIをインストールしたばかりですが、さらに便利な機能を満載した「AUTOMATIC1111/stable-diffusion-webui」が登場しました。
下記のような機能はじめ、多くの改良が施されています。
・VRAM 4GBのNVIDIA GPUでも動作可能
・崩れがちな顔をGFPGANで自動補正
・RealESRGANによる自然な解像度拡大(アップスケール)
・プロンプト、パラメータの影響などを確認できるツール群
・画像の一部だけ描き変えることができる(Inpaint)
・生成したときのプロンプト・パラメータを確認できる
・もちろんGUIで簡単操作
・その他いろいろ
https://github.com/AUTOMATIC1111/stable-diffusion-webui
これは試すしかないですね。
まずは、Python, Git, CUDAのインストールが必要ですが、NMKD Stable Diffusion GUIをインストールしていたのでここは省略できました。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
で、ダウンロード。(Webページからzipダウンロードして回答するのでも可)
StableDiffusion-Gui-v1.2.0¥Data¥modelckpt をstable-diffusion-webuiフォルダ直下にコピー。
さらに下記よりGFPGANv1.3のモデルをダウンロードして、stable-diffusion-webuiフォルダ直下に配置。
https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.3.pth
web-user.bat を必要に応じて編集して実行すると、インストールとWEBサーバの起動が自動で行われます。
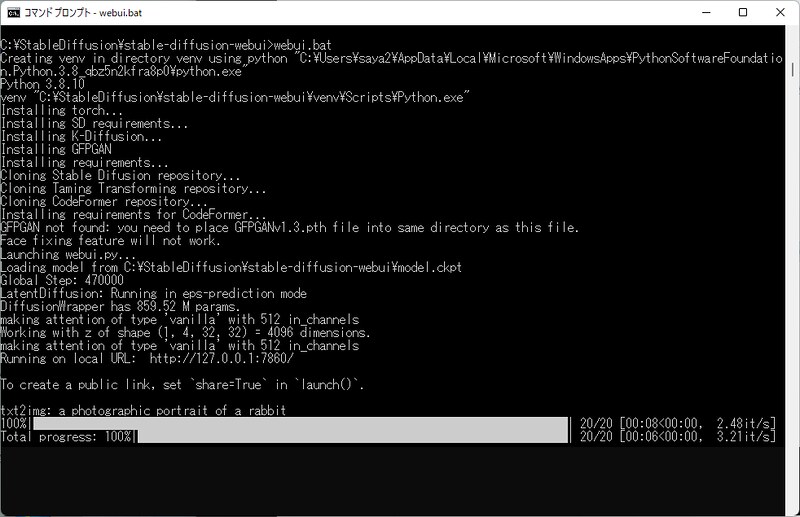
表示された http://127.0.0.1:7860/ にブラウザでアクセスすると、Stable Diffusion web UIが起動。とても簡単ですね。
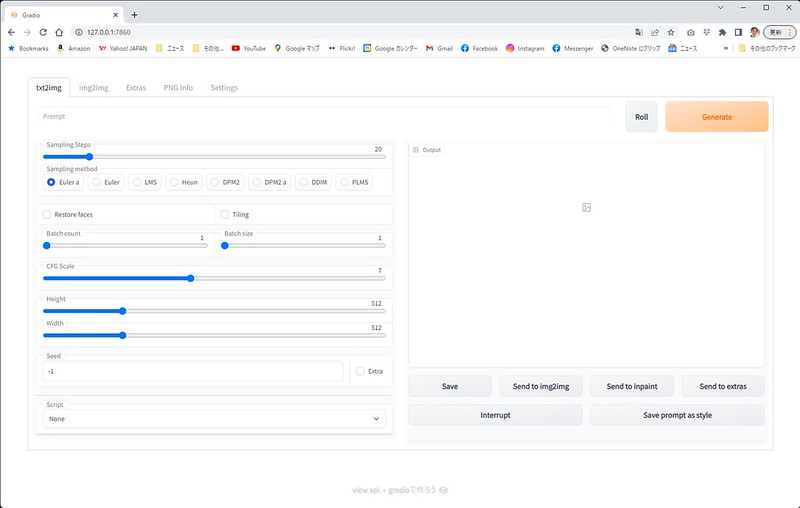
上にあるPromptのところに、生成したい画像の説明文章(プロンプト)を英語で入れて、「Generate」ボタンを押すと、画像が生成されます。
「Roll」ボタンは、プロンプトに作家名をランダムに挿入できるようです。ジャンルは「Settings」タブの中の設定で指定可能。

「Restore faces」にチェックを入れると顔の補正機能が働きます。

同じSeedとプロンプトで、同じ絵を生成するようで、「Restore faces」のオンオフでその効果も確認できます。

「Batch count」に指定した枚数の画像が一度に生成されます。
動作はかなり速くて、1枚の生成に10秒もかかりませんでした。
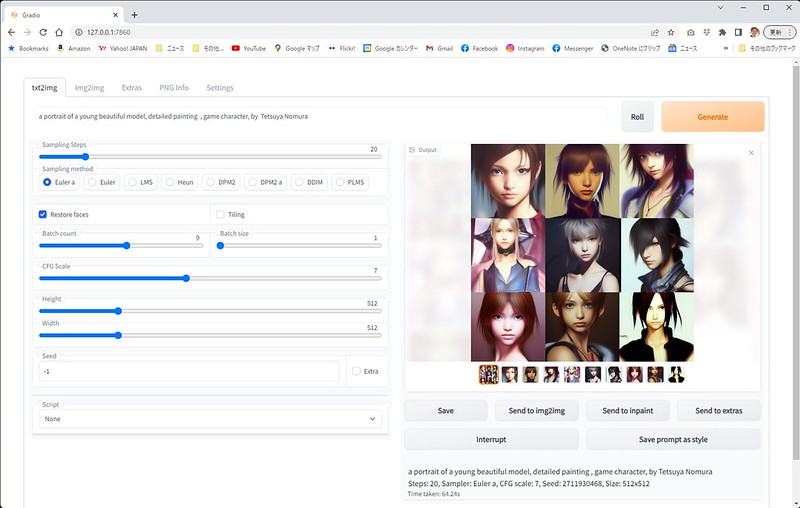
確かに変な顔が生成される確率が減った感じがします。
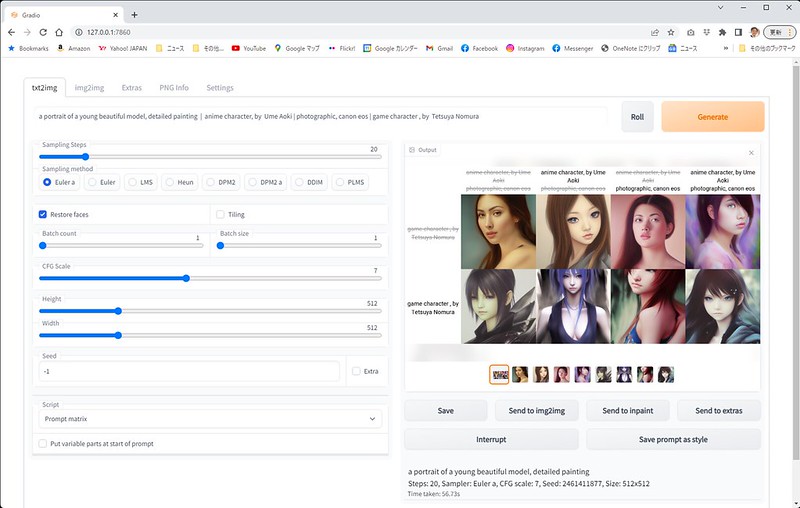
Scriptの欄ではPrompt matrixやX/Y plotを選ぶことができ、プロンプトやパラメータを変化させて、その効果を確認することができます。

プロンプトに|で区切って候補を羅列すると、それを組み合わせ変化させた画像が生成されます。
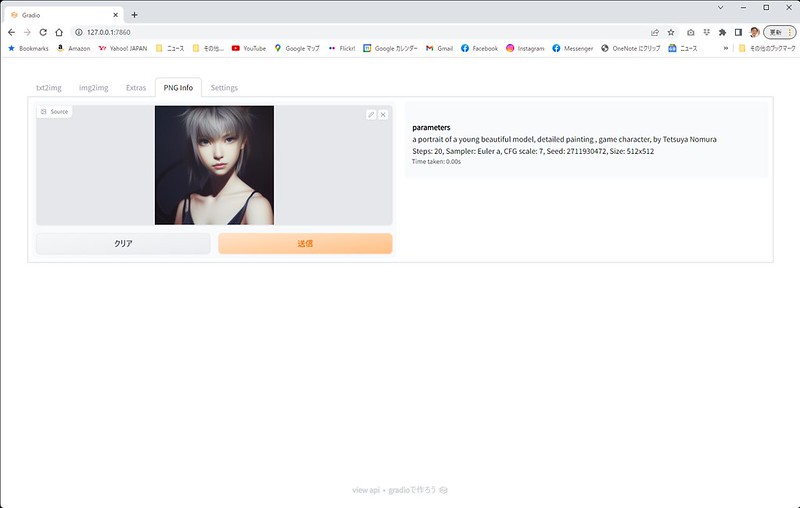
ちなみに生成した画像は、outputsフォルダ内に生成されますが、ファイル名にプロンプトやパラメータの情報を持っており、「PNG Info」タブに画像をドラッグ&ドロップして「送信」を押すと、プロンプトとパラメータが確認できます。

元画像から新画像を生成する「img2img」のタブもあります。画像をドラッグ&ドロップするか、「txt2img」タブで「Send to img2img」を押して元画像とすることもできます。「Denoising strength」で元画像の変化量を設定して、プロンプトを入力して「Generate」ボタンを押すと、新画像が表示されます。

Denoising strength 0.3

Denoising strength 0.7
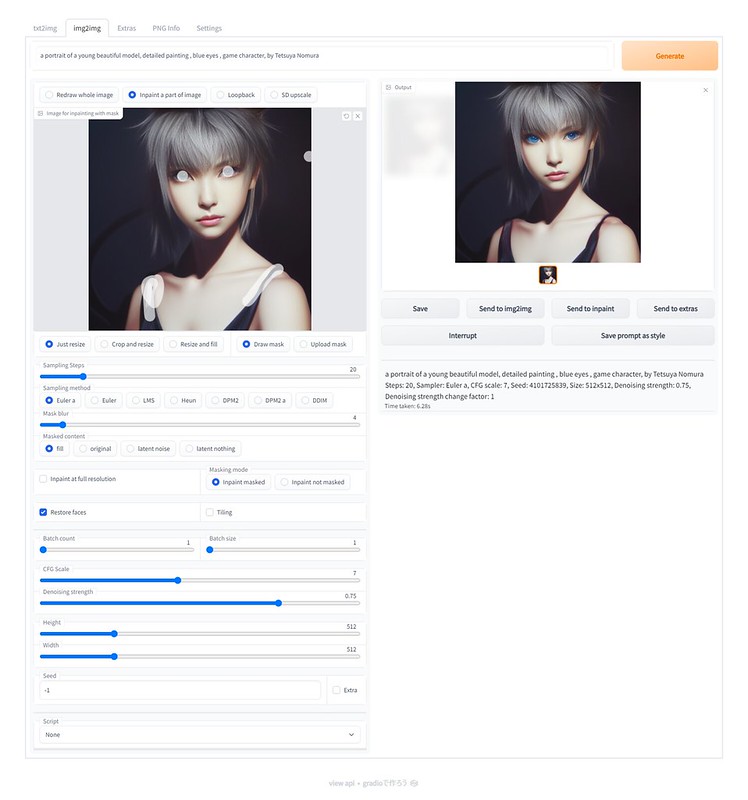
「Send to inpaint」を押して、「img2img」タブの「Inpaint a part of image」で変更したいところを塗って、「Generate」を押すと、そこだけ変更した画像を生成することができます。

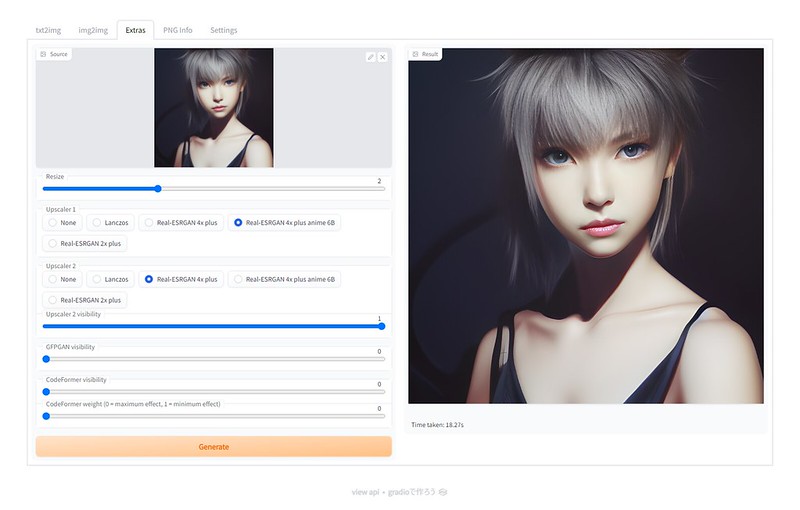
「Send to extras」を押して、「Extras」タブに移動すると、画像のアップスケールができます。

解像感を向上させたとてもきれいなアップスケールができますね。

「Settings」タブにはいろいろな設定があったり、この他にも様々な機能があったりしますね。色々試してみたいと思います。
これはStable Diffusionの決定版ですね!
と言いたいところですが、まさに日々新しいのが出てきている状況ですね。日本語対応で追加学習されたモデル搭載の「rinnakk/japanese-stable-diffusion」も気になりますし、そのうち動画生成までAIでとか思っていたら、もう「andreasjansson/stable-diffusion-animation」とか「deforum/deforum_stable_diffusion」とか出てきてますし。
被写体を簡単に写し撮るカメラの発明みたいなもので、どんどん使いやすい道具になって、これから表現が大きく変わる予感がします。
関連投稿:
 アニメキャラクター生成し放題 Waifu Diffusion のモデルを #StableDiffusion web UI (AUTOMATIC1111) に入れて、AIを2次元絵師に
アニメキャラクター生成し放題 Waifu Diffusion のモデルを #StableDiffusion web UI (AUTOMATIC1111) に入れて、AIを2次元絵師に
 Apple M1/M2 Mac に Stable Diffusion web UI をインストールする方法 #StableDiffusion #BRAV5
Apple M1/M2 Mac に Stable Diffusion web UI をインストールする方法 #StableDiffusion #BRAV5
 Stable Diffusion web UI v1.6.0 で 次世代 #StableDiffusion (#SDXL) が簡単に使えるようになりました
Stable Diffusion web UI v1.6.0 で 次世代 #StableDiffusion (#SDXL) が簡単に使えるようになりました
 NVIDIA RTX搭載Windows PCで GUIで簡単に #StableDiffusion を使える NMKD Stable Diffusion GUI が登場
NVIDIA RTX搭載Windows PCで GUIで簡単に #StableDiffusion を使える NMKD Stable Diffusion GUI が登場
ピンバック: アニメキャラクター生成し放題 Waifu Diffusion のモデルを #StableDiffusion web UI (AUTOMATIC1111) に入れて、AIを2次元絵師に | Digital Life Innovator
ピンバック: 画像生成AIで大きな絵を作成する #StableDiffusion の絵を継ぎ足し拡大して複雑な絵が描ける Hua | Digital Life Innovator