


画像生成サービス「NovelAI Diffusion」がリリースされ、その2次元キャラクター生成のクオリティが話題になっていましたが、有償サービスのみで無償で使うことはできないようです。その学習の一部として使った掲示板「Danbooru」が無断転載サイトとなっているため、物議を醸していましたが、Danbooru自体の問題はともかく、インターネットに公開されている画像は学習元として利用されることを覚悟しないといけない感じですね(著作権的にはAI学習に利用するのは問題にならないし、学習されたものを取り戻す手段がないため)。
そんなDanbooruを含めた画像を学習して、2次元イラスト生成にチューニングされた学習済みモデルとして、Waifu Diffusionというのもあります。ここで公開されているモデルをStable Diffusion web UI (AUTOMATIC1111) に入れて動かしてみました。
https://github.com/harubaru/waifu-diffusion/tree/main/docs/en/weights/danbooru-7-09-2022
からwd-v1-2-full-ema.ckptをダウンロードします。なかなかつながらないですが、つながったらGoogle Driveが速いですね。
Stable Diffusion web UI (AUTOMATIC1111) を最新化(再インストールが無難)して、ダウンロードした wd-v1-2-full-ema.ckpt を stable-diffusion-webui\models\Stable-diffusion に置きます。
起動してSettingsタブを選ぶと、ものすごく設定が増えてました(使い方調べないと…)。
Stable Diffusion checkpointの項目を wd-v1-2-full-ema.ckpt に変更すると、デフォルトのものの代わりにWaifu Diffusionの学習済みモデルを使うようになります。(追記:今はモデルを画面のトップで選択できるようになっています)
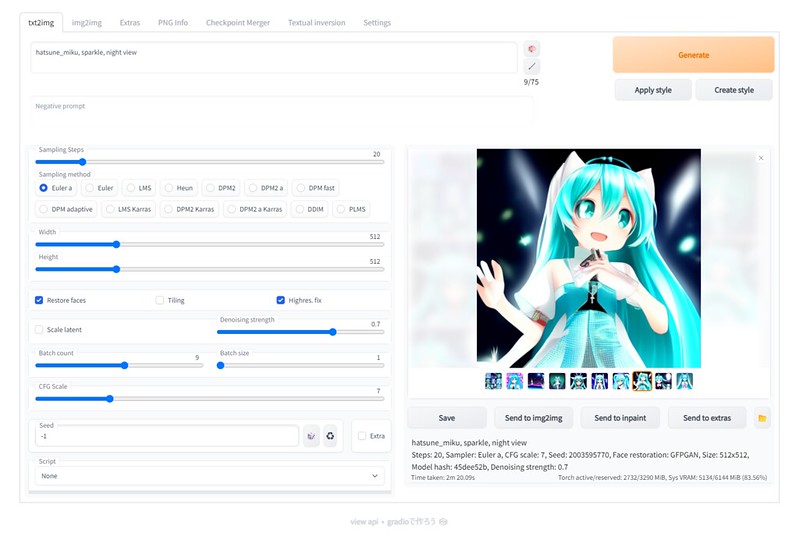
キャラクター名なども学習しているので、試しに初音ミクとかシンプルにプロンプトに入れてみると、それっぽいキャラクターが次々生成されました。
良いなと思った画像では手の部分がおかしかったので、Send to inpaintを押して、
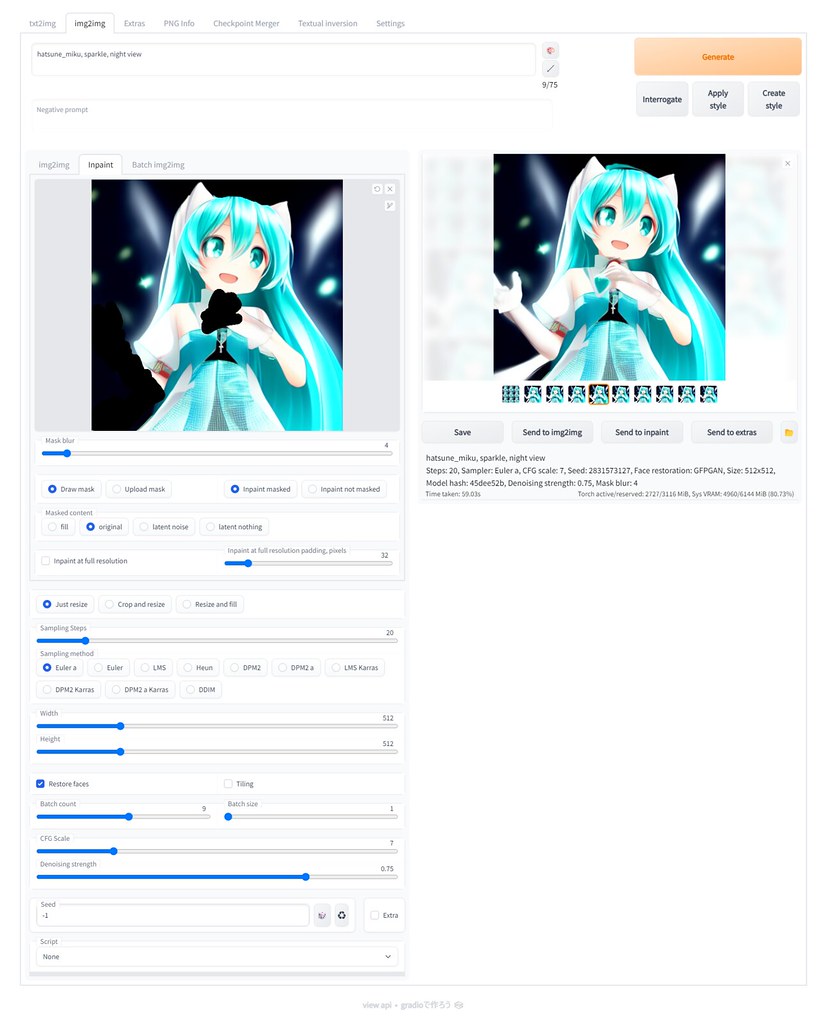
書き直してほしいところを塗りつぶして、Generateを押すと、色々書き直してくれるので、良さげなものを選びました。
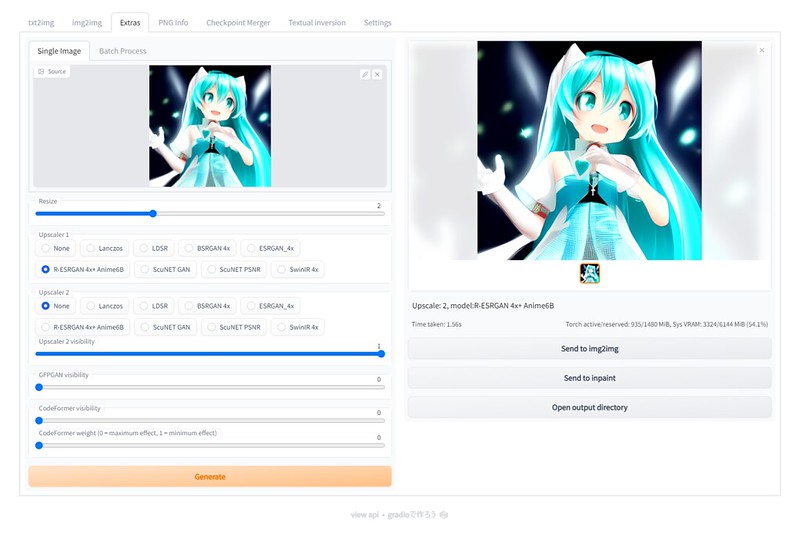
Send to extrasを押して、高精細化処理。これだけでこのような画像が生成できます。


キャラクター名を指定するのでは色々問題があるかもしれないので、オリジナルのキャラクターを生成するために、色々プロンプトを入力して生成してみます。(プロンプトはDanbooruで使われているタグを並べると良い感じになるそう)
Stable Diffusion web UI (AUTOMATIC1111)では、不適切画像のフィルターが外されているので、不適切なキーワードを入れたらダメですよ(笑)。
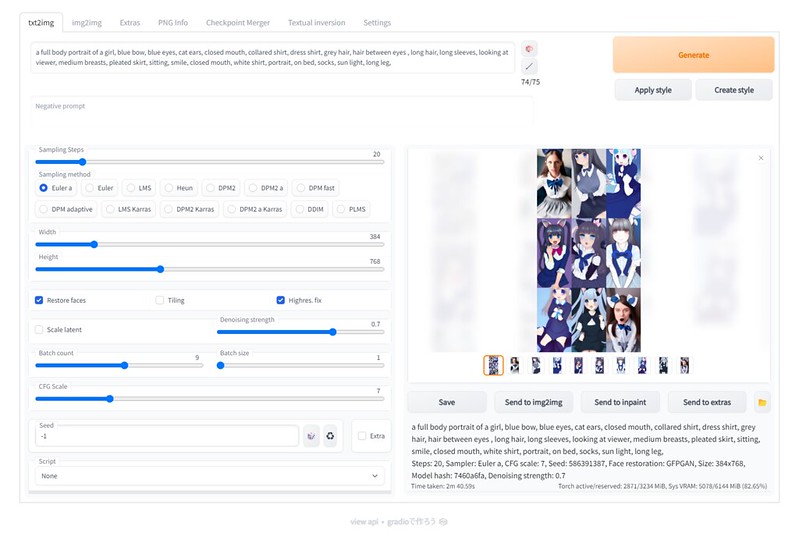
ほぼ同じプロンプトをStable Diffusionの学習済みモデルで試したときと比較すると、かなり2次元画像生成の成功率が高くなっているのがわかります。

好きな画像が出てくるまでガチャを引いて、好きな画像が出てきたら、Send to img2imgを押して、似たような画像からさらにガチャを引くことができます。

出てきた画像(修正なし)はこんな感じ。なかなかのクオリティですね。



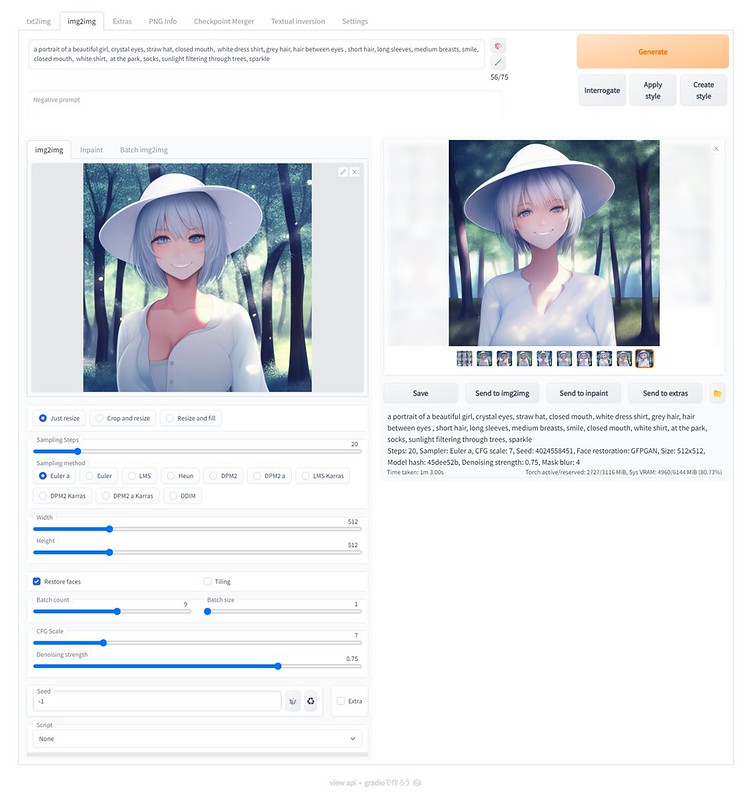
少しプロンプトを変えていくと全く違った画像に。


以下、似たようなプロンプトからAI絵師が生成した春夏秋冬の作例を載せておきます。








短時間で色々出てくるので、ガチャが面白いですね。
ちなみにStable Diffusion web UI (AUTOMATIC1111) は、専用のツールで簡単にApple Silicon Macでも動くようになっていました。スピードはNVIDIA RTX搭載PCと比べるとやはりかなり遅いですが。
trinart_stable_diffusion_v2の学習済みモデルも良さげです(良いのが出てくる確率は低い感じですが)。
https://huggingface.co/naclbit/trinart_stable_diffusion_v2/blob/main/trinart2_step115000.ckpt

(追記) ついにNovelAIエミュレーションとか。やばいですね。
https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/2017
上記と同じプロンプトなのに、失敗例が少なく、クオリティが違いすぎる。








NovelAIエミュレーションのAI作例やプロンプトについては、こちらの記事で紹介しています。
関連投稿:
 #StableDiffusion VRAM4GBのGPUでも動作 顔補正 アップスケール プロンプト比較 一部補正 などなど便利機能満載の Stable Diffusion web UI (AUTOMATIC1111)
#StableDiffusion VRAM4GBのGPUでも動作 顔補正 アップスケール プロンプト比較 一部補正 などなど便利機能満載の Stable Diffusion web UI (AUTOMATIC1111)
 Apple M1/M2 Mac に Stable Diffusion web UI をインストールする方法 #StableDiffusion #BRAV5
Apple M1/M2 Mac に Stable Diffusion web UI をインストールする方法 #StableDiffusion #BRAV5
 Stable Diffusion web UI v1.6.0 で 次世代 #StableDiffusion (#SDXL) が簡単に使えるようになりました
Stable Diffusion web UI v1.6.0 で 次世代 #StableDiffusion (#SDXL) が簡単に使えるようになりました
 #StableDiffusion Web UI #NovelAI エミュレーション の AI作例 を プロンプト とともに紹介
#StableDiffusion Web UI #NovelAI エミュレーション の AI作例 を プロンプト とともに紹介
ピンバック: #StableDiffusion Web UI #NovelAI エミュレーション の AI作例 を プロンプト とともに紹介 | Digital Life Innovator
ピンバック: #StableDiffusion の NovelAI超え Anything v3.0 と Midjourney v4風 Openjourney で ミュシャ風?絵画生成比較 | Digital Life Innovator
ピンバック: 2022年の振り返り | Digital Life Innovator