LCM(Latent Consistency Model)やADD(Adversarial Diffusion Distillation)といった技術で、生成AIで非常に少ないステップ数でまともな画像が生成できるようになってきました。これらを使ってほぼリアルタイムに画像生成したり、動画生成が短時間化されたりしていますね。
Mac上のStable Diffusion web UIで、既存のモデルを使いつつ、LoRAでこれらの技術を使って画像生成を高速化してみました。
LCM-LoRA Weightsは下記からダウンロードできます。SDXL用とSD1.5用があるので使い分けます。
https://civitai.com/models/195519/lcm-lora-weights-stable-diffusion-acceleration-module
ADDを使ったsd_xl_turbo_loraは下記からダウンロードできます。Stability AIのSDXL-TurboをLoRA化したものです。
https://huggingface.co/shiroppo/sd_xl_turbo_lora
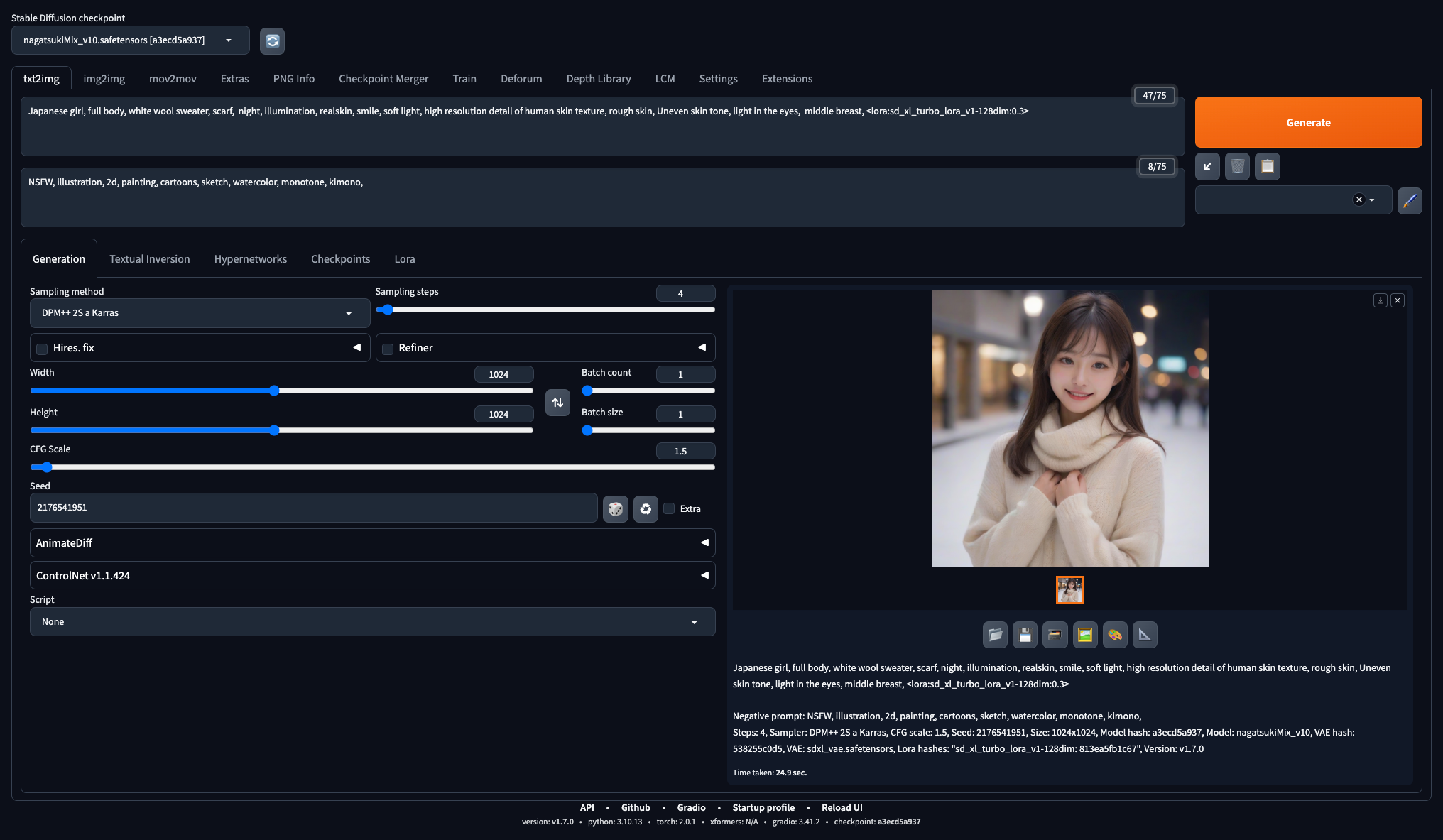
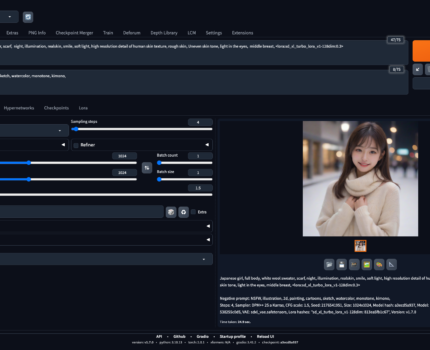
まずは実写系のモデル(nagatsuki_mix v1.0)で使ってみます。

こちらは普通に生成したもの。1024×1024の解像度で、30 STEPで3分15秒かかりました。(CFGは3.5)

<lora:LCM_LoRA_Weights:0.3>を追加して、6 STEP、CFG 1.5で生成。生成時間は38秒で、ステップ数の違いそのまま5倍高速化しました。
LoRAはかけすぎると自然でなくなるので0.3くらいが良い感じでした。ステップは6くらいで自然になる感じでした。

ちなみに同じ6 STEP, CFG1.5でLoRAをかけないとこんな感じで、だいぶ甘く書き込みもない感じです。

こちらは<lora:sd_xl_turbo_lora_v1-128dim:0.3>をかけたもの。4 STEP、CFG 1.5です。生成時間は25秒で7.8倍高速です。
こちらもLoRAは0.3くらいが自然でした。3 STEPでは少し甘いところが会ったので4 STEPで。

<lora:LCM_LoRA_Weights:0.3>で4 STEPだとこんな感じ。まだ少し甘い感じなので、sd_xl_turbo_loraの方がより高速な印象です。
アニメ風モデル(bluePencilXL_v010)でも試してみました。

LoRAなし 30 STEPで3分19秒

<lora:LCM_LoRA_Weights:0.3> 6 STEP 45秒

LoRAなし 6 STEP 全体的にかなり甘いですね。

<lora:sd_xl_turbo_lora_v1-128dim:0.3> 4 STEP 25秒

<lora:LCM_LoRA_Weights:0.3> 4 STEP まだ目や手がうまく描けていませんね。
モデルが違ってもほぼ同じ傾向でした。
NVIDIAのGPUを使ったらもっと爆速になるようですが、MacでもSDXLになってから遅かった画像生成がかなり高速になり便利になりました。LCMを組み込んだモデルも出てきているようですが、LoRAなら専用モデルでなくても使えるのが良いですね(同じものが高速で出力できるわけでもないし、相性等もあるようですが)。
関連投稿:
 Stable Diffusion web UI v1.6.0 で 次世代 #StableDiffusion (#SDXL) が簡単に使えるようになりました
Stable Diffusion web UI v1.6.0 で 次世代 #StableDiffusion (#SDXL) が簡単に使えるようになりました
 #ComfyUI で AIポートレート&AI動画作成 #StableDiffusion #LCM #StableVideoDiffusion
#ComfyUI で AIポートレート&AI動画作成 #StableDiffusion #LCM #StableVideoDiffusion
 #StableDiffusion XL (#SDXL) の ControlNet や チューニングモデル・マージモデル を試してみました
#StableDiffusion XL (#SDXL) の ControlNet や チューニングモデル・マージモデル を試してみました
 Macローカルの Flux.1 dev + Comfyui で LoRA や IP Adapter などの ControlNet を動かしてみました #Flux #Mac
Macローカルの Flux.1 dev + Comfyui で LoRA や IP Adapter などの ControlNet を動かしてみました #Flux #Mac
ピンバック: 2023年の振り返り | Digital Life Innovator